Yet another post about the Battlesnake project I’ve been working on while diving in Crystal lang.
This is a quick continuation of yesterday’s post about storing data in a DB. I mentioned why I took a performance hit and the solution implemented was to persist the data to DB from a background job. The idea is that enqueuing the jobs to Redis would ideally perform better than waiting for a DB write.
Again, FYI the code is on GitHub.
Mosquito
The Crytal Sidekiq port was a tempting option for a background task runner, but I went with mosquito-cr/mosquito. My initializer looks like this:
require "mosquito"
Mosquito.configure do |settings|
settings.redis_url = (ENV["REDIS_URL"]? || "redis://localhost:6379")
end
Since initializers are required by src/app.cr (more about this on a previous post) I can now enqueue the job where I once persisted directly to DB. Snippets from all of this below:
# Replaces `Turn.create(...)`
PersistTurnJob.new(
path: env.request.path,
context_json: env.params.json.to_json
).enqueue
# src/jobs/persist_turn_job.cr
require "mosquito"
class PersistTurnJob < ApplicationJob
params(path : String, context_json : String)
def trace_perform
context = BattleSnake::Context.from_json(context_json)
dead = context.board.snakes.find { |s| s.id == context.you.id }.nil?
turn = Turn.create(
game_id: context.game.id,
snake_id: context.you.id,
context: context_json,
path: path,
dead: dead
)
end
end
In order to have OpenTelemetry tracing of the jobs I inherit from my ApplicationJob.
# src/jobs/application_job.cr
require "mosquito"
# Base class for jobs in the app. Overrides `perform` so that jobs can
# implement `trace_perform` instead. This will allow for OpenTelemetry tracing
# if available, otherwise the job will be executed as it would if it overrides
# `perform` (mosquito standard). If someone does override `perform` on the job
# it will also have no behavior effect, other than tracing not taking place.
abstract class ApplicationJob < Mosquito::QueuedJob
def perform
if ENV["HONEYCOMB_API_KEY"]?.presence
OpenTelemetry.trace self.class.to_s do |span|
span.kind = :internal
trace_perform
end
else
trace_perform
end
end
end
Worker
Until now the app produced only one executable, which was the API server. The worker that runs these background jobs is src/worker.cr file and looks like this:
require "./battle_snake/**"
require "./strategy/**"
require "dotenv"
Dotenv.load if File.exists?(".env")
require "./initializers/**"
require "./models/**"
require "./jobs/**"
Mosquito::Runner.start
It requires all dependencies and starts the mosquito runner, but how to work on it locally?
I have a sam.cr task in place that helps me with local develpment. I tweaked make sam dev to spin up two Sentry runners, and it continues to work seamlessly with both development executables + livereload (livecompile?) again.
Dockerfile
I use a Docker deployment on DigitalOcean’s App Platform (previous post about this), so I need to change the Dockerfile so that both executables are compiled & included there. This allows to execute either one from the same image passing in the command to override the default ENTRYPOINT (reference).
It now looks like this:
# Build image
FROM crystallang/crystal:1.7.2-alpine as builder
WORKDIR /opt
# Cache dependencies
COPY ./shard.yml ./shard.lock /opt/
RUN shards install -v
# Build a binary
COPY . /opt/
RUN crystal build --static --release ./src/app.cr
RUN crystal build --static --release ./src/worker.cr
RUN crystal build --static --release ./src/money_hack.cr
# ===============
# Result image with one layer
FROM alpine:latest
WORKDIR /
COPY --from=builder /opt/app .
COPY --from=builder /opt/worker .
COPY --from=builder /opt/money_hack .
ENTRYPOINT ["./money_hack"]
It’s now compiling src/app.cr, src/worker.cr, and… src/money_hack.cr? Well, I already mentioned I’m not trying to spend more money than needed on this project.
My solution was to run both the server and the worker on the same node/droplet. There are many disadvantages to this so I don’t recommend this practice as a rule of thumb (hence the name src/money_hack.cr). Managing this with Kemal/Mosquito configs or independent horizontal scaling as needed are likely better solutions.
#! /usr/bin/env crystal
#
# Runs both the server and worker executables in separate fibers to avoid
# independent deployments. Motivation is saving costs
#
channel = Channel(Nil).new
spawns = ["./app -p 8080", "./worker"].map do |command|
spawn do
res = system command
channel.send(nil) unless res
end
end
channel.receive
Resource consumption & performance
First of all, there’s now two executables running on the same droplet that used to only run the API server. These are the insights of the small instance running 512 MB RAM | 1 vCPU x 1 (last 7 days).
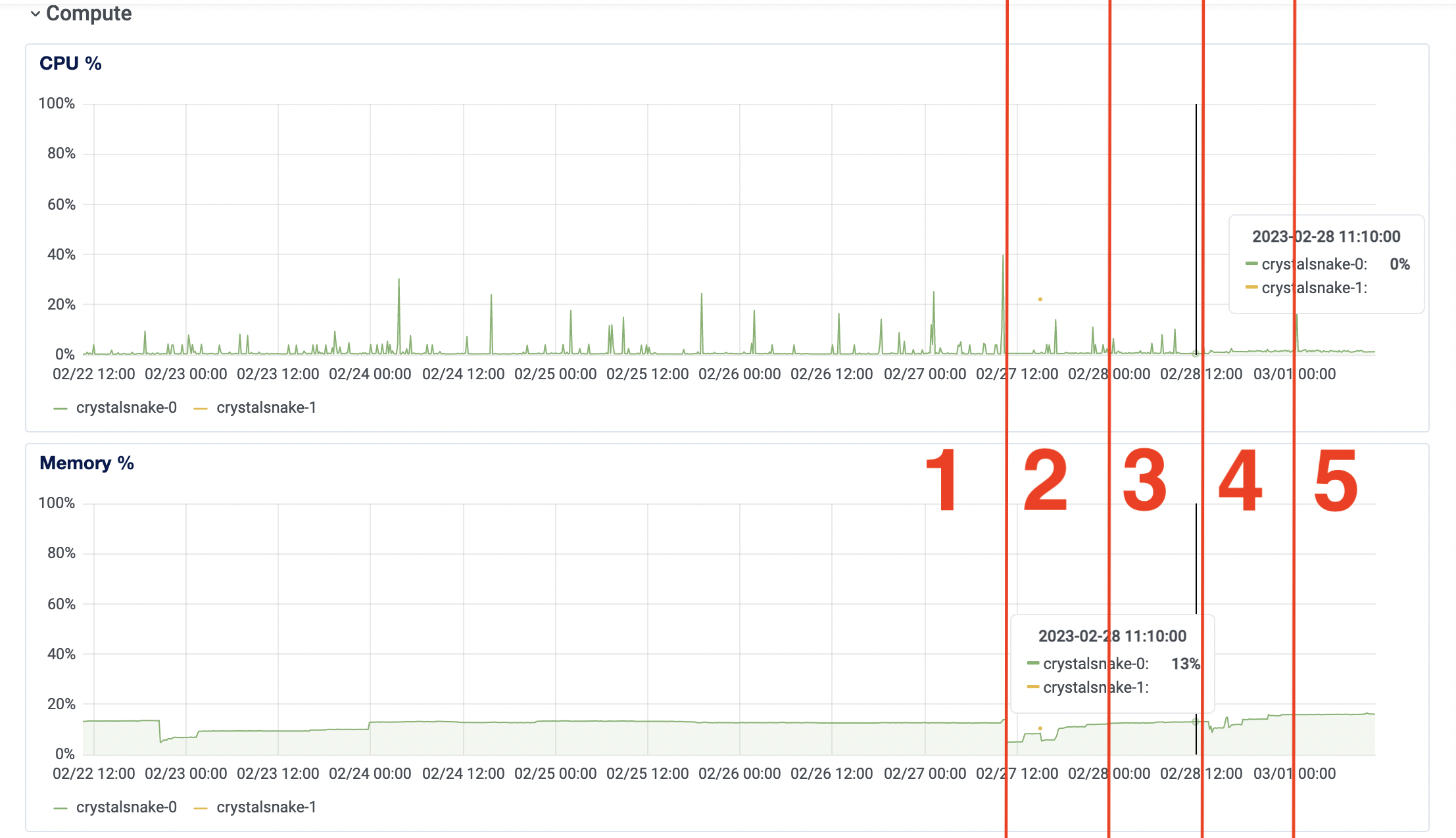
I marked in red the (approximate) regions to explain them better.
| Region | Memory average | CPU average | Notes |
|---|---|---|---|
| 1 | 13% | 0%-1% | Pre-data persistance (no DB) |
| 2 | variable | variable | development (debug/errors/deployments) |
| 3 | 13% | 1%-2% | sync DB persistance (prev post) |
| 4 | variable | variable | development (debug/errors/deployments) |
| 5 | 16% | 1%-2% | Background job persistance |
In region 1 there’s ~13% memory usage and that remains unchanged during region 3. With the worker processing jobs region 4 did consume ~16% memory, which is very little difference IMO. CPU usage in region 1 was 0% and 1% at times (5min granularity). With both persitance implementations on region 3 and 5 it bumped up to 1% and 2% values.
All of this tells me that we could (in theory) refactor money_hack.cr to have many workers in parallel before getting close to maxing out the hardware capabilities. Definitely not necessary for now, specially since the bottleneck is DB/Redis hardware. Just a funny situation to think about.
Telemetry comparison
The COUNT, P50, P95, and P99 of traces across the last few days below
BEFORE DB PERSISTANCE

SYNC DB PERSISTANCE

ASYNC WORKER DB PERSISTANCE

That’s great! ~2x better in P50, ~2.5x better in P95, and ~5x better in P99. Nothing compares to raw Crystal code execution with sub-millisecond response times, but this isn’t bad in any way considering we have everything integrated in the project.
Below is the telemetry on the job execution too. An alternative would be aggregating/querying logs I guess, but with the existing integration it’s an easy way to measure them too.

It makes sense to see the jobs perform similar to the sync DB persistance telemetry data. Reassures the assumption (widely known/used approach) that DB requests are slower than Redis in this scenario.
Conclusions
The app is starting to look sturdy to me, as in there are a few moving pieces now and it performs nicely (fast and reliable). It’s also a joy to work with Crystal code.
I have one more post in mind for the series, at least for a while, so I’m excited about sharing that sometime soon.
Pura vida.